- 要旨 市販TTS読み上げソフト+RPA+自作ツールで音声発声サーバーを再構築
ネックスピーカーへの音声読み上げはchromeの標準音声読み上げAPIで読み上げていたのだが、そろそろもうちょいよい声にしたいと思ったので 市販の読み上げソフトを使うことを検討した。
元々技術的にはやれるだろうと思っていたのだがようやくこっち側へのやる気が出たので数日で作り込みした。
音声APIは仕事でやるなら当然ライセンスでlinuxサーバーででも動かすのが正解なのだろうが、個人用途ではそこまでやるのはちょっとなんなので 個人用プロダクトを購入してRPAで自動化という方向にした。
RPAは少し前に調べたのだが、この周りのビジネスは「大雑把にはフリーで自動化できるけど、細かいことをしたいならサブスクリプションしてね」という 感じなので、こっちもフリー範囲でなんとかしてうまく出来ない範囲はnodeかPowerShellで書いてしまうことにする。
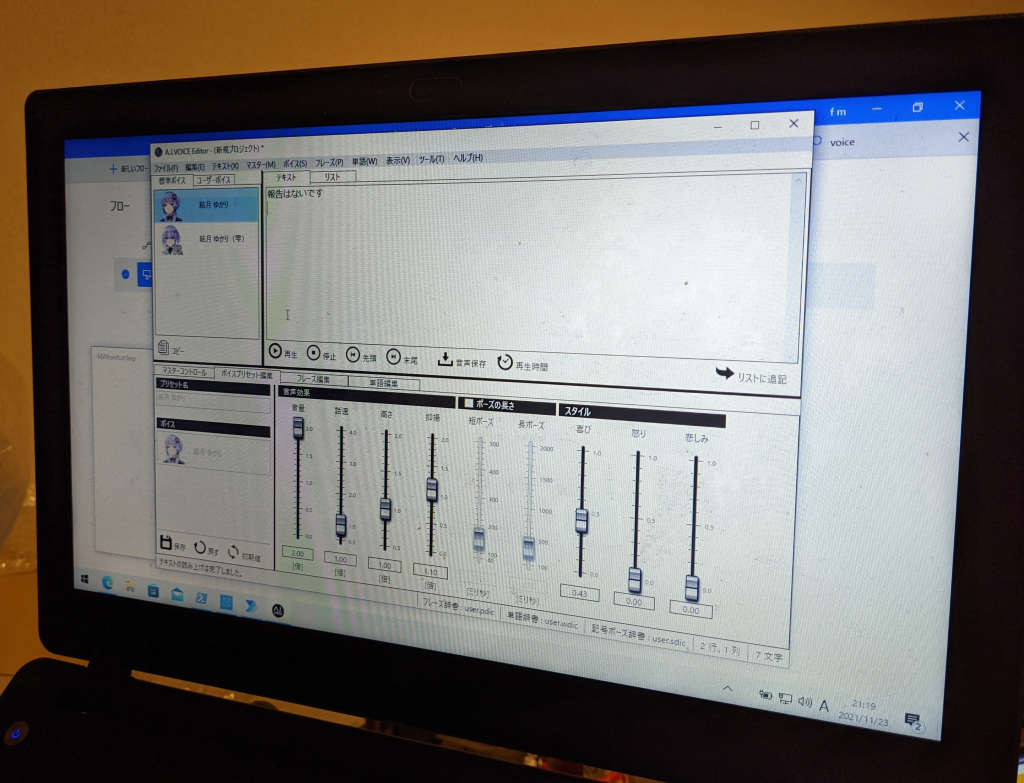
音声読み上げにはエーアイ社のAI voiceのパッケージをダウンロード購入。
RPAは無難にMSのPower Automate Desktopを使用。この際RPAの組み方も慣れておきたいし。
結局制限として、
- 読み上げソフトはUI操作しかできない(APIなら恐らくlinuxとかでの商用ライセンス)
- Power Automate Desktopはスクリプト起動がUI操作しかできない(APIならMSアカウントのビジネスライセンス要)
という話を個人用に手軽に動かすということで、その間をnodeとかPowerShellとかでつぎはぎすることにした。
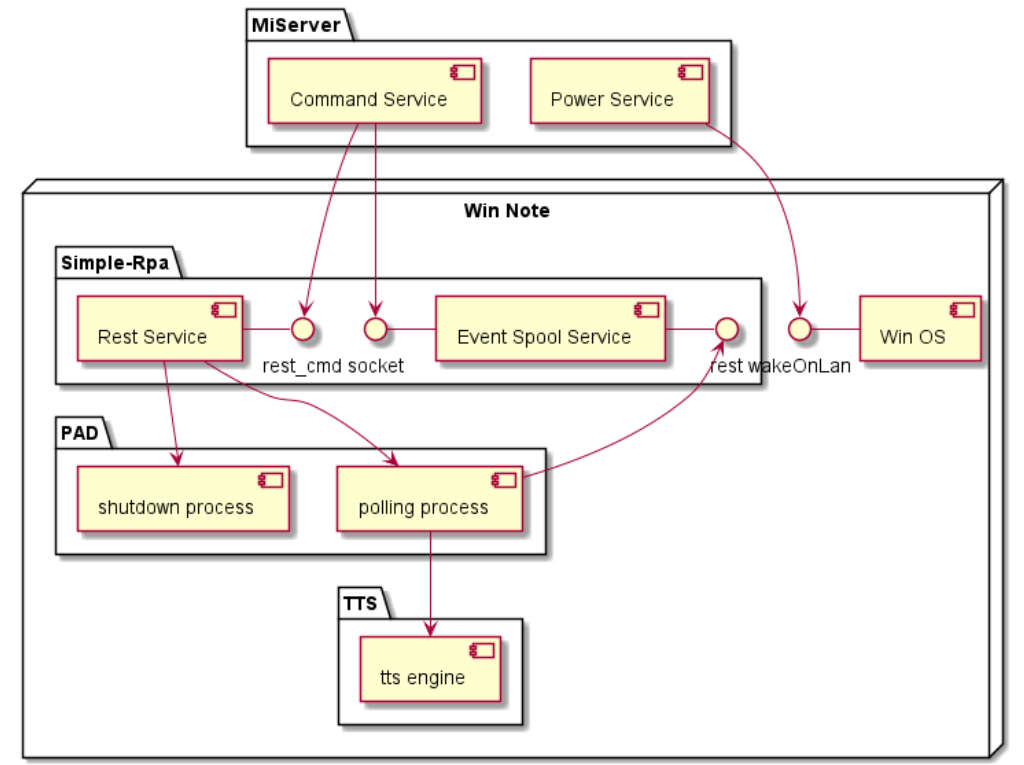
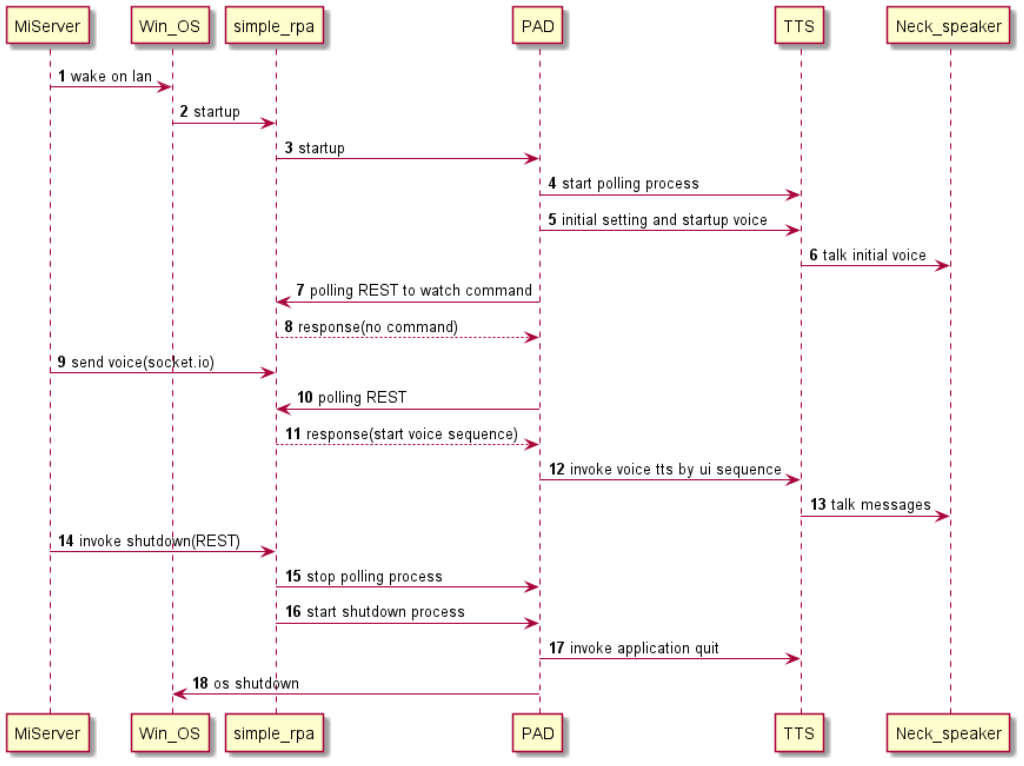
やっぱりこの手のつぎはぎは結構試行錯誤になって面倒。仕事ではやっちゃいかん手順だな。。。
でも抑揚とかを調整できる音声読み上げソフトだとよい声で、もうちょっと作り込んでやろうという気もするのでよいな。